
TL;DR: Built Vibe Meter 2.0 to track Claude Code subscription usage by parsing JSON-L files and counting tokens with a SIMD-accelerated BPE tokenizer. No official API exists, so I approximated usage by counting every token. The project grew to 47K lines of Swift with 92% test coverage, all written with CC using “thinking” triggers and modern Swift idioms.
The Shock: How Much Am I Actually Using?
What started as a simple idea to explain vibe coding to new people is slowly growing up. With version 2 of Vibe Meter, I added full support for Anthropic’s subscription. While v1 only focused on cost display for Cursor, for version 2 I wanted to add support for CC. This turned out to be much more of an adventure than I initially thought.
The Problem: Flying Blind Without APIs
Anthropic has both API endpoints with straightforward pricing. They also offer subscriptions where especially in the max version you get around 900 requests in a 5-hour window. I was curious:
- A) How much that would actually cost if it would be API calls
- B) How many requests you actually have open in that 5-hour window
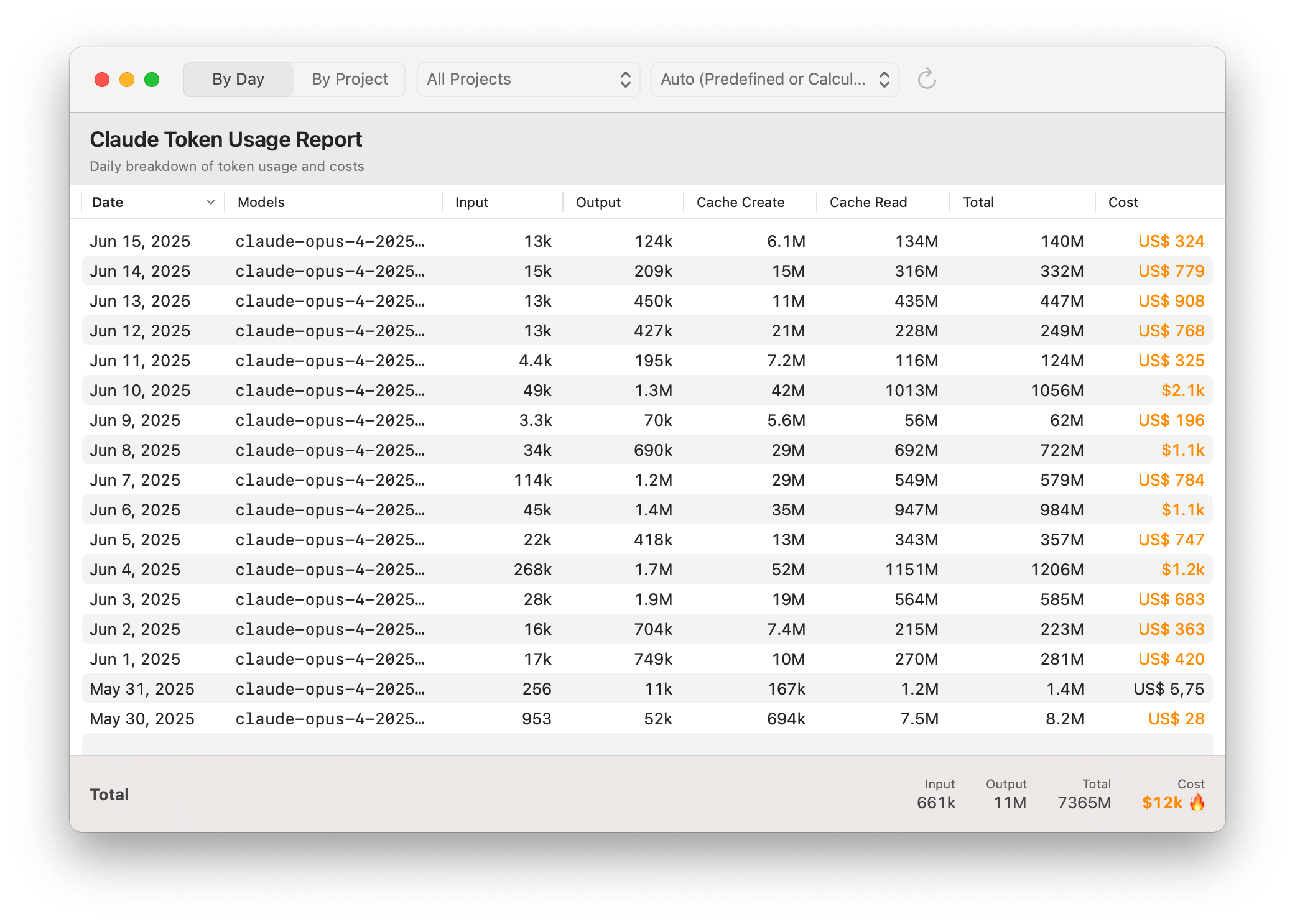
Well, turns out this is not easy at all. There is no API for that, there’s no cost control, there’s not even a hidden private API or something on the website that you could look at. The only way literally is to count the individual tokens that are sent to the LLM and then approximate how much is left. We also have to approximate when a window starts. As you can see, this was the start of a little adventure.
The Solution Journey: From Collaboration to SIMD
Learning from the Community
Luckily, I wasn’t alone. There were other people that were already curious and interested in that idea, so I could learn from various open source projects like ccusage, which pioneered the approach of parsing Claude’s JSON-L files. Counting tokens also is not as simple as you would think. Claude Code writes all interactions with their server into so-called JSON-L files which can be in the hundreds of megabytes large. So I spent a lot of time tweaking the parser, or dare I say me and Claude did.
SIMD Operations for Performance
During the process I even started using SIMD operations, something which I only darkly remember got support in Swift but now it’s crucial to offer a speedy parsing that doesn’t bog down your CPU.
The most impressive optimization is the vectorized lookup table that uses SIMD16 (16-byte vectors) for fast pattern matching:
// VibeMeter/Core/Utilities/Tiktoken/CoreBPESIMD.swift:222-281
private struct VectorizedBytePairLookup {
// Pre-computed SIMD vectors for common byte pairs
private let pairVectors: [SIMD16<UInt8>: [(length: Int, rank: Int)]]
init(bytePairRanks: [Data: Int]) {
// Build SIMD lookup table for byte sequences
for (data, rank) in bytePairRanks {
if data.count > 16 { continue } // Skip sequences longer than SIMD width
// Create a SIMD vector padded with zeros
var vector = SIMD16<UInt8>(repeating: 0)
data.withUnsafeBytes { (bytes: UnsafeRawBufferPointer) in
for i in 0 ..< min(data.count, 16) {
vector[i] = bytes[i]
}
}
vectors[vector]?.append((length: data.count, rank: rank))
}
}
}This approach allows us to compare 16 bytes at once instead of doing byte-by-byte comparisons, dramatically speeding up the token counting process.
Token Counting with BPE
As a basis, I used the open source TikToken BPE tokenizer that is actually from OpenAI. There’s no public tokenizer project from Anthropic. However, the tokens are similar enough that we can use this project and still get fairly accurate results.
BPE (Byte Pair Encoding) is a compression algorithm adapted for tokenization in NLP. It breaks text into subword units (tokens), often capturing whole words or common prefixes/suffixes. Instead of just splitting on whitespace or characters, BPE builds a vocabulary of frequently seen pairs of characters or subwords. This allows models to handle unknown words, rare terms, and typos more gracefully.
Key Insights: Thinking Triggers and Fresh Context
Agentic engineering, as I prefer to say, requires even more clear thinking. I evolved my approach where I would use Claude Code and ask it to think hard about the problem. The thinking keyword is key because it triggers how much token Claude uses to actually think about the problem. There are various levels how you can trigger thinking, with Ultra Think being the highest level.
As I work more with Claude Code, I tend to slow down, ask it to plan, present options, ultrathink, and then pick the best one. And always using a fresh context. Much better results.
Look at these examples:
Took a few planning prompts each but then the code one-shots and works perfect.
Pro Tip: One trick to get better results in Claude Code is to use the various “thinking” triggers, with ultrathink being the boss. Check out the extended thinking tips in the Anthropic documentation for more details.
🚀 Side Quest: The Birth of llm.codes
While building Vibe Meter 2.0, I ran into a weird issue where Claude would argue with me that one cannot build nice toolbars in SwiftUI. This ultimately inspired me to build llm.codes, a way to feed Claude up-to-date information so it produces better code. You can read more about this journey in my post: llm.codes: Transform Your Developer Docs into LLM-Optimized References.
Modern Swift Refactoring
In the 2.0 refactor, I also put a better effort on using modern Swift idioms, and most I did that by Claude teaching modern Swift via a new Markdown file that I fed to him and asked him to refactor my codebase using modern Swift idioms. I shared this and many other knowledge files in my new agent rules repository.
The Results: 47K Lines, 92% Coverage
VibeMeter has grown into a substantial project:
- App code: 24,529 lines
- Test code: 22,560 lines
- Total: 47,089 lines across 218 Swift files
- Test coverage ratio: 92% (tests are nearly as large as the app itself!)
With this release, I also added support for macOS 141 which was quite simple.
Get Vibe Meter 2.0
Note: Vibe Meter is still on the pre-release channel for now, there’s a few edge-cases I wanna get right before making it 2.0 official, but it’s close!
Get it here and switch update channel for the preview!
Footnotes
-
The only issue was with automatic observation tracking, which is macOS 15+ only. Learn more about this hidden gem in my post: Automatic Observation Tracking in UIKit and AppKit. ↩