tl;dr: I built and shipped a brand-new feature live (in ~1 hour), watch how I approach agentic engineering with codex
Join me for an unfiltered look at building Arena - a live coding session where you can see my development process in action, unscripted. Thanks to Eleanor Berger for motivating me to do this video and for organizing the live event!
{% youtube https://www.youtube.com/watch?v=68BS5GCRcBo %}
What we built
🤖 Heads up! This is an AI-Assisted summary.
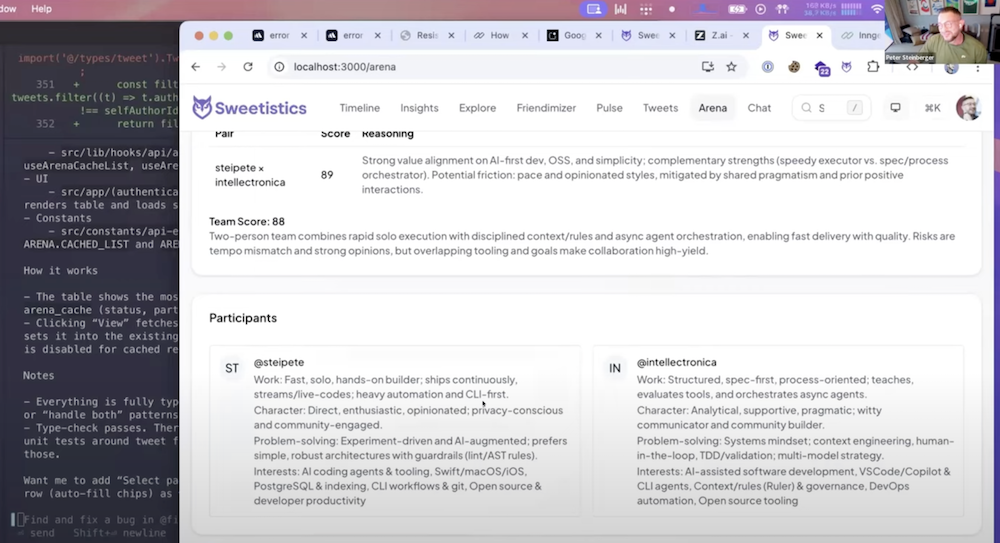
- Feature: Arena — a new feature in my upcoming project, to see how well 2–4 users from X match
- Input: Twitter/X user handles
- Pipeline: fetch N tweets per user (shares a 1,000-tweet budget), strip to necessary fields, run profile analysis, then score compatibility (per pair + whole team)
- UX: user picker + “Analyze” button, results table, cached runs selectable under the search box
- Infra touches: DB migration for
arena_cache, long-running job in the background, streaming UI, auth-guarded page
I managed to complete the feature in ~1h, and we got a pair score of 89 for me and @intellectronica.
Stack & Setup
-
Model workflow: codex (OpenAI/GPT-5) for coding sessions; it eagerly reads the codebase and generally “does the right thing” without handheld file lists. I keep a separate Claude-style flow for some web searching, but for repo work codex is the star.
-
Sessions: start fresh for big features, run multiple agent windows in parallel; switch tasks while one is thinking.
-
Branching: work directly on
mainwith atomic commits. Merge conflicts + worktrees cost speed; small, well-scoped commits keep things safe. -
Tooling:
-
Docs ingestion: pull only what’s needed, prefer markdown via a crawler over raw HTML to save tokens.
-
Validation: schema validation on inputs; fail fast and surface helpful messages.
Tactics that mattered
- Keep the agent context clean. Minimize tool noise and only inject docs when needed; markdown > HTML to conserve context.
- Let codex plan on demand. It proposes next steps that are usually solid; green-light them in sequence.
- Cache long tasks early. Add a table + background job queue before you polish UI; this saves you from re-running expensive analysis.
- Copy-paste errors verbatim. Don’t over-explain; just drop logs in and let the agent fix what broke.
- Comments as spec. Ask for clear intent comments near tricky code; they’re for you and for the agent on the next session.
- Write tests afterwards, not first. These agents are great at back-filling tests once the shape exists, and that’s usually enough to catch regressions.
- Work on
main, commit surgically. You still get speed with safety. Backups + Git are your safety net. - Avoid local models for this workload. Context and stability matter more than shaving milliseconds.
- CLIs beat MCPs. A 2-hour CLI wrapper (logs, API pulls) pays for itself and keeps context small.
- Small “proof” projects unblock big features. If streaming or a protocol is hard, build a tiny in-repo example that works, then transplant.
Q&A highlights
- Why Codex over Claude Code? Codex actually reads more of the repo without handholding; requires fewer “look here, then there” hints. Claude still useful for search/web, but for coding Codex felt faster end-to-end.
- Do you branch? Not for features at this stage. Main + disciplined commits is faster and - counterintuitively - safer for rapid iteration.
- Manual approvals for agent actions? No. That becomes “Windows Vista prompts.” Use Git + backups; review diffs; move fast.
- Repo prompts & MCP servers? Nice idea, but they bloat context and introduce fragility. Lean instructions + small CLIs work better.
- Compaction & long sessions? Plan features to fit the context. If you expect many loops (e.g., test repairs), use the flow that compacts well - or split the task.
If you want to read more about my agent workflow, check my AI development post here.
For more advanced prompting techniques with GPT-5, also check out the OpenAI GPT-5 Prompting Guide.